






こんにちは。AI担当になりつつある三代です!
今回は、「知ってはいるがなかなか時間がなくて勉強できない」という方が多い、AIによる映像生成についてご紹介します。
最近話題となっていますが、まだこれといった使い方が決まっているわけでもなく、様々な生成フローが研究されている段階です。
皆様のモチベーションを高めるために、まずAIによる動画制作でどのような作品が作れるのか、一つのゴールをご紹介します。
現状最新の生成AIを使いまくってMV的なものを作ってみました(内容はめちゃくちゃ)🙌
— Arata Fukoe (@Arata_Fukoe) July 7, 2024
Tools Utilized ↓
Music : ChatGPT,Sunoai
Video : DreamMachine,Gen-3,Kling
Image :MJ,SD
Edit : Ps,Ae
特に人物とかは大きい画面で見ると粗が目立ちますが、使い方次第でなんとか誤魔化せるかなといった感じ🤔 pic.twitter.com/9DzENHP4sV
こちらの映像はすべてAIを使ってつくられたものです。
非常に高いクオリティで海外で大バズリし最終的にForbesに掲載されるまでに至りました。
https://www.forbes.com/sites/charliefink/2024/07/11/limp-bizkits-ai-music-video-ai-pirate-horror-fantasy-found-footage-from-the-future-a-treat-from-tokyo/
かっこいい音楽とマッチした映像で頭に残る映像ですよね。しかし投稿をよく見てみると、音楽すらもAIによって作られたことがわかります。
X投稿より以下の内容が読み取れました。
- 音楽:ChatGPT(おそらく歌詞),Suno AI(音楽生成AI)
- 映像:DreamMachine,Runway Gen-3,Kling
- 元になる画像:Midjourney StableDiffusion
- 最終的な映像編集:PhotoshopとAfterEffects
これらのAIなどを駆使して1つの作品に仕上げたということかと思います。
ほんとに使えるツールはすべて使う、、、という感じですが、あわせ技でこんなクオリティが出せるというのは正直驚きですよね。
今回の記事ではもちろんここまでのものを作るわけでは有りませんが、どのような考え方で取り組めばよいのか、という足がかりとして読んで頂ければと思います。
まずは画像生成AIの歴史から
AIによる動画生成、画像生成についてご存じない方もいらっしゃるかと思いますので、まずは最新の情報にキャッチアップしていただくためにこれまでの流れを解説させていただきます。
AIによる画像生成として一番我々の身近で話題になったのは2022年のMidjourneyが最初かと思います。
Discordのbotを通じて生成を依頼するというものでした。生成を依頼すると4つの画像が生成されてきます。その中から好みのものを選んでいき、似たものをまた4枚出していき、といった具合でブラッシュアップしていくというスタイルでした。
この時は偶然の産物を楽しむフェーズであり、こんなの出来た!と個人的に楽しむ用途として使われていました。
その後、他の人が作成した素晴らしい画に対して、どうやったらその画を出せるのかと言った探究から、画の再現のニーズが高まりました。ここから偶然の産物ではなく、狙った絵を再現する「プロンプトエンジニアリング」が始まったわけです。
今現在はその再現を超えて、シーンを完全に制御し狙った画を出力させ、映画のワンシーンやCMのワンカットを完全に補完するまでになりつつあります。
つまり、どんなものが出てくるかな、と想像するのではなく、こんな顔のこんな髪型の人がこんな服で、こんなポーズをして、とすべてが頭に想像できている状態で、それを画に変換させるといったフェーズが2025年です。
AI画像生成の進化
Midjourneyで生成された画像から選択・ブラッシュアップを繰り返し、偶然の出会いを楽しむ段階
素晴らしい画像を意図的に再現するため、プロンプト設計技術が発展した段階
人物の顔・髪型・服装・ポーズまで精密に指定でき、映像制作に活用できる段階
Midnurneyと同じ2022年にはStable Diffusiont、そしてChatGPTで有名なOpenAIが作ったDALL·E 2というものも出てきています。
MidJourneyはどちらかというと油絵のようなボワボワとしてテイストのため、それはそれとしてよいのですが、表現が限られてしまっていました。
DALL-E 2はMidjourneyに比べ、より写実的な画像を生成するものでした。
そしてStable Diffusionはオープンソースとしてリリースされ、モデル内部のソースコードが公開されていたことから、自らのPCの中にインストールしてカスタマイズすることが可能となり、画像生成技術の幅を広げるきっかけになったサービスでした。
2023年にOpenAIがChatGPT内での画像生成が可能なDALL-E 3をリリースし、既存のChatGPT Plus(20ドル/月)ユーザーであれば追加費用無しで使えるようになりました。
ここからだれでも気軽に画像生成ができるようになりました。それまではギークな人しか触っていなかった画像生成AIを、初めてChatGPTから触ったという方も多いのではないでしょうか。
画像生成AIの進化 (2022-2023)
そして2024年、突出してクオリティの高い画像を生成するサービスが出てきました。それが以下のサービスです。
これだけ知っておけばとりあえずOK
これらは後ほど扱うため名前の紹介だけにとどめておきます。
動画生成AIサービス
動画生成に関しては画像生成のようにちゃんと使えるようになったのは直近1年ほどといった印象です。ですのまだ歴史は浅く、今からキャッチアップしていけば乗り遅れることはないでしょう!
2024年時点でちゃんとしたクオリティのものが出せるものは以下になります。
2024年後半の主要動画生成AI
それぞれシーンごとに得意不得意があり、それらすべてを理解して使いこなすのはとても難しいです。
そしてそれを理解するためにはやはりたくさん使う必要がありますが、動画生成は画像生成と違い、コストはとても高いです。ちょっと出してみよう、で数十円どんどん消えていくため丸一日触っていると数千円レベルは簡単に消えてしまいますので注意が必要です。
実践
早速ですが実践してみましょう!
どのサービスを使えばいいか迷うかと思いますが、どれでもよいのでとりあえず1つだけ課金して使い始めてみて、なんとなく理解したら、次のサービスを使ってみると良いと思います。
ある程度得意なシーンが肌感覚で掴めてくると思います。
Klingにこんなプロンプトを渡してみました。
宇宙から来た未来生物が渋谷の街を破壊しながら練り歩く様子
パシフィック・リムを感じますね(笑)
同じプロンプトをDreamMachineに入れてみました。
このように全く同じプロンプトでもモデルによって解釈が変わるわけです。
今回のプロンプトでは、未来生物の数もそうですし、どのような未来生物なのか、といったモンスターのテイスト自体も指定をしていません。その部分は生成AIモデルにお任せしてしまっているわけです。
このおまかせする範囲が増えれば増える程に出力は不安定になり、仕事では使いづらいものとなります。
こんなシーンを作りたいのに!と思って何回リクエストを出しても、なかなか欲しい絵が出てこないわけです。
例えば1つ目の映像で言えば、渋谷と言っているのにどちらかというと新宿駅の南口交差点のほうが近いですよね。
では明確に渋谷とわかるスクランブル交差点にしよう!と、”スクランブル交差点”などの固有名詞をプロンプトに入れても、これまたモデルによってスクランブル交差点の解釈が異なる場合があります。
渋谷ほど有名であれば問題ないかもしれませんが、最近完成したばかりの施設のプロモーション動画を作りたい、みたいなケースでは過去の知識しか持たないAIは、新しい施設の固有名詞を理解することはできないでしょう。
そこで解決策になるのがI2Vという生成方式です。
I2Vとは
(AI生成/実写)
(プロンプト)
(I2Vツール)
I2VとはImage to Videoの略称です。前章のようにテキストから動画にすることをT2V(Text to Video)と言います。
違いとしては先に別のサービスで画像を生成、それを元に動画化をしてもらうのがI2Vという方式です。
勘の良い方は気がついたかもしれませんが、I2Vで扱う画像はAI生成した画像でないと行けないという決まりはないため、実際に撮影したデータを元にしてそれを動かすといったことも可能になります。
基本的に昨今の動画生成ブームではこのI2Vを基本の制作フローとして取り入れているケースが多いです。
理由としては、テキストから動画にする場合と比べてシーンの縛りが容易になることが挙げられます。
例えば、「赤い服を着た犬」というプロンプトでは、犬の犬種もそうですし、赤のどの程度の赤なのかと考え始めたらきりが有りません。
それを一度画像として生成してしまうことで、画としての大枠を確定させ、動きのみの指示(プロンプト)に集中できるようになるわけです。
おすすめ画像生成サービス
アイデアを考える
(例: 夕日の海辺の犬)
プロンプトの作成を依頼
(ChatGPTなど)
画像生成サービスに入力
(ImageFXなど)
・Gemini内では画像は1:1アスペクト比
・英語プロンプト作成にはAIツールの活用がおすすめ
画像を生成した後に、それを動かすというアプローチで動画を作るとうまく行きやすいというお話をさせていただきましたが、数多あるサービスでどれがよいのでしょうか?
今はChatGPTやxAIのGrok3でも無料で画像が生成できます。
上記で紹介させていただいたKlingやDreamMachineでもクレジットを消費することで高品質な画像生成が可能です。
そんななかズバリおすすめなのは上記スライドにもあるDeepMind Imagen-3です。
こちらはGeminiというAIとのチャット内で無料で使うことが可能です。
しかしチャット内で生成される画像はアスペクト比が1:1になってしまい少々使いづらいです。
こちらのImageFXというサービスから利用することでアスペクト比を16:9にすることができ、同時に4つまで生成できるので様々なプロンプトを試してみたいときに便利につかうことができます。
注意点としてはプロンプトは英語しか受け付けないため、基本的には外部でプロンプトを作ってそれをペーストして画像を生成するというアプローチになります。
それでは早速使ってみましょう!
プロンプトは「ミニチュアの玩具列車セットと赤い玩具の建物が、シンプルな木の床の上に置かれている。背景にはかすかな光があり、暖かい黄色の色調が広がっている。」というものを英語にしたものです。

いかがでしょうか?かなりクオリティの高いものが作れたのではないでしょうか?
Googleアカウントさえあればこれが無料で使えてしまうので恐ろしい時代になったなと感じてしまいます。
当然リアルすぎる画像が作れてしまうため、悪用に使われないために電子透かしという技術が採用されており、人間には感知できない形で、画像がAIで生成されたことを示すタグのようなものが埋め込まれているそうです。
プロンプトの推敲
上記の画像でも問題ないのですが、例えばホラー映画のワンシーンとして挿入したいので、より冷たい印象にしたい、薄暗くしたいという別の要望が出てきたとします。
その場合はこちらの元のプロンプトをChatGPT等のAIサービスに頼んでより洗練されたものにアップデートしてもらいましょう!
自身で試したい方向けに、元のプロンプトも貼り付けておきます。
Miniature toy train set and red toy buildings, sitting on a simple wood flooring, faint light in the background, warm yellow tones
今回はGrok3を使って編集してみたいと思います。
依頼した内容はこちら
画像生成プロンプトを作成したいです。 以下のプロンプトに私の要望を反映させたものを作成してください。 プロンプトは英語と日本語それぞれ作成してください。
Miniature toy train set and red toy buildings, sitting on a simple wood flooring, faint light in the background, warm yellow tones.
こちらのプロンプトをホラー映画のワンシーンで使いたいと思っています。 背景が暖色の光になっているので、寒色に変え、寒く冷たい印象にしてください。 その他ホラー映画にふさわしい表現にしてください。おもちゃに少し血がついている等。

英語だけ出してしまうと、こちらが完全に理解できない場合があるので、念の為日本語を出しています。
これにより違う方向にプロンプトが編集されてしまった際に、画像を生成してまた戻っての1ラリー分を削減できるため、同時出しがおすすめです!
結果がこちら
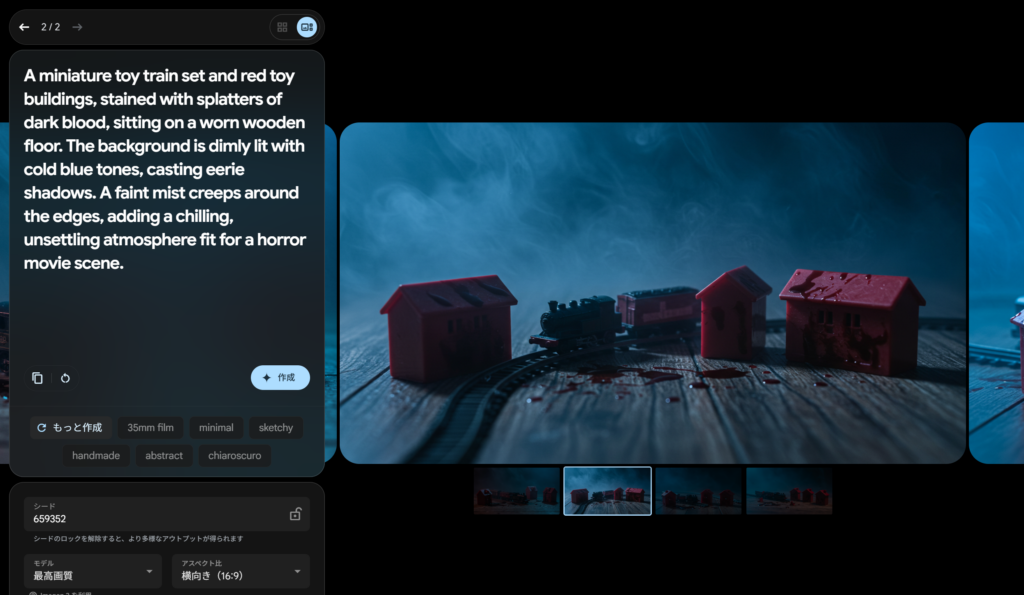
いい感じにホラー映画のワンシーンのような画が出来上がりました。それではこちらの画像を使って動画にしていきましょう!
動画生成
画像生成のときもそうでしたが、基本的にプロンプトは英語のほうがうまく動作します。
まだ早期アクセス版のリリースされているため(2025年3月14日現在)すぐに試せませんが、現時点で最高峰のモデルのDeepMindのVeo2というモデルでは日本語でプロンプトを書くと、謎のおじさんがフレームのど真ん中に出てくるというバグがあったりします(笑)
ですので基本的に画像生成、映像生成において、クオリティを上げたい場合は英語プロンプト!とおぼえておきましょう。
ですので今回も動画にするためのプロンプトをAIに作ってもらうことにしましょう。
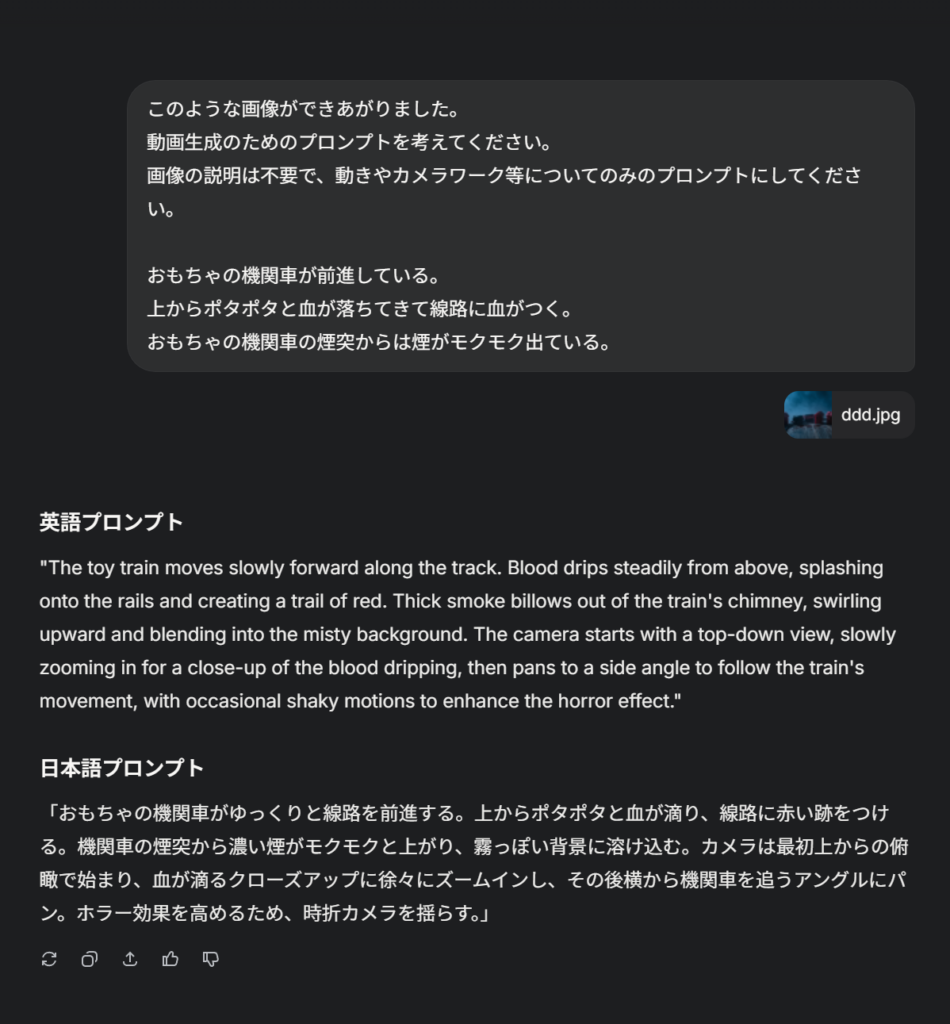
それでは出来上がったプロンプトをLuma DreamMachineに入れて作成をしてみます。
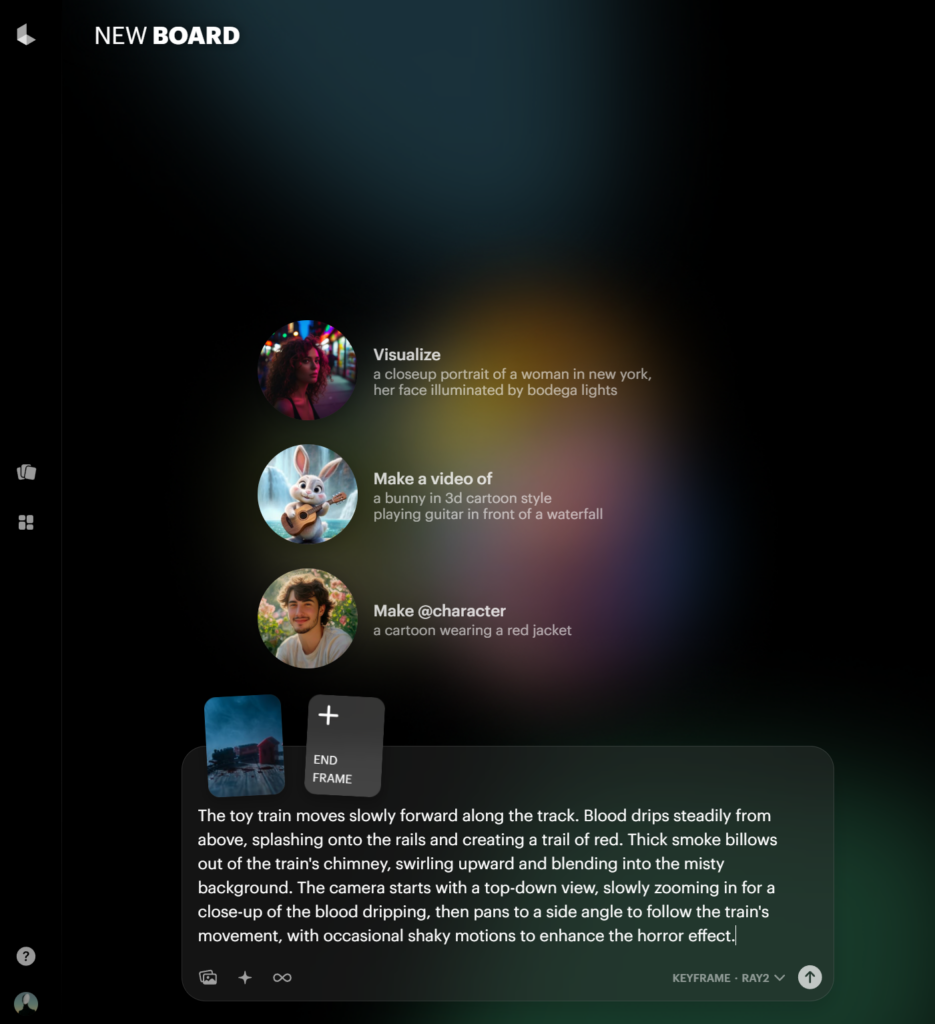
画像をドラッグアンドドロップすると自動で開始フレームとして設定されます。
プロンプトを入れて実行ボタンをおしてしばらく待ちましょう。(5分前後)
2パターン出来上がりました!
こちらは煙突の煙の表現が素敵ですね。被写界深度の表現も素晴らしいです。
こちらはカメラがドリーアウトしてくれていますね。おもちゃの機関車らしく小刻みにカタカタ揺れている表現もプロンプトで指示していませんが、軽さをAIが理解しているということだなと関心しました。
DreamMachineは1080pで5秒作成し、そのまま追加で5秒ずつ延長させたり、4Kまでアップスケーリングさせることが可能です。
ちょっとここまで暗いシーンばかりになってしまったので次の5秒で明るいシーンに返させてみましょう!
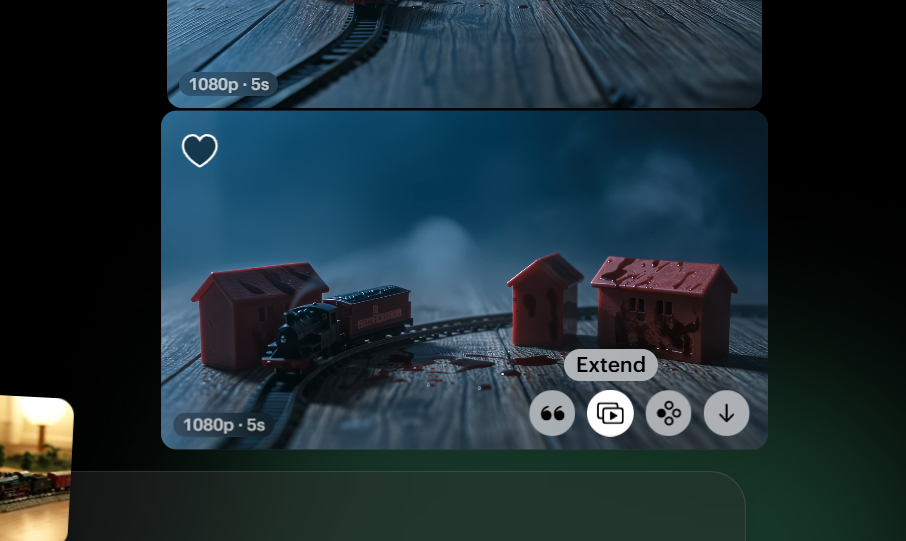
出来上がった画像のExtendボタンを押すことで延長が可能です。
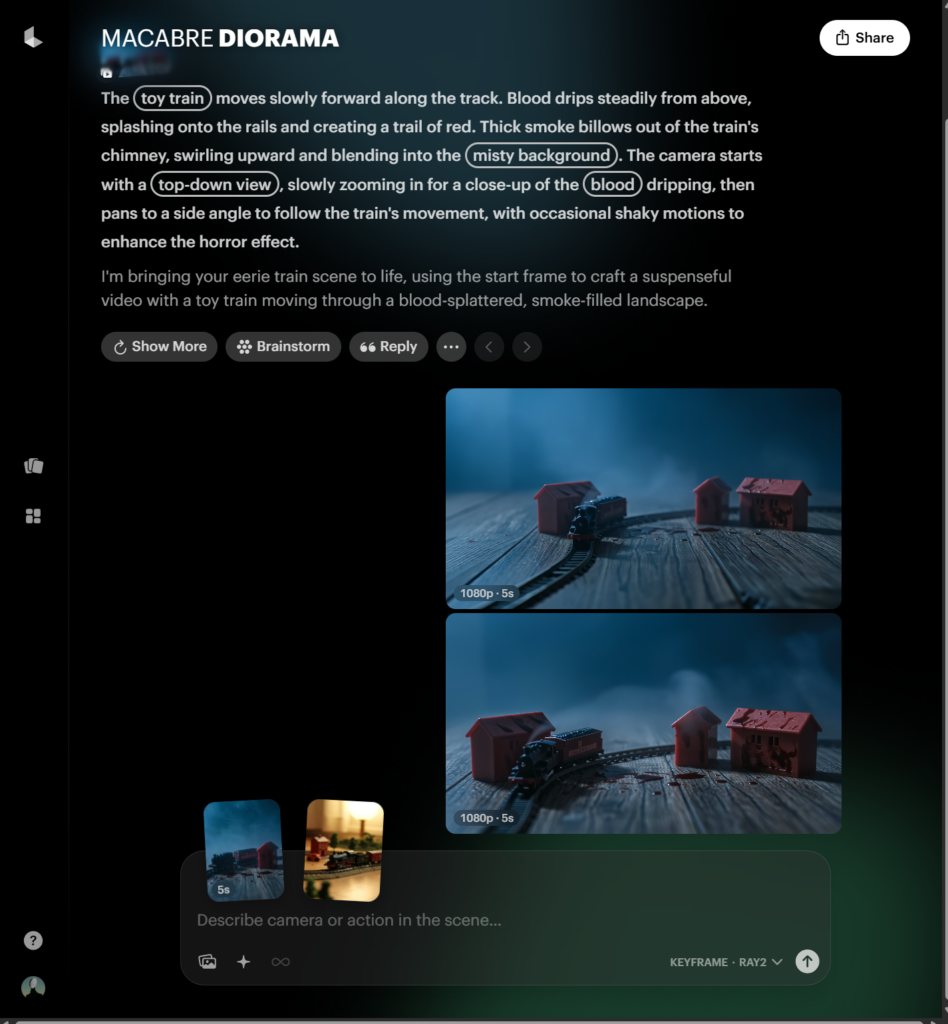
延長の場合は始まりのフレームと終わりのフレームを指定することになります(終わりのフレーム未指定も可)。
その間のフレームをAIが補完をしてくれるイメージです。始まりのフレームを先程作成した5秒の動画の終わりのフレーム、終わりのフレームを一番最初にImageFXで生成した明るいおもちゃの画像にしてみたいと思います。
Exntendを選択すると自動で開始フレームは割り当てられるため動画からの切り出し等は不要です。
プロンプトはシンプルに以下としました。
The toy train runs to the left and arrives at a bright room.
なかなかつなげるのは難しかったようです。。。
客車がレールの外を爆走しているのがちょっとおもしろいですが、このようになかなかきれいに制御するのが難しいところはあります。
指示の仕方が雑になるとこのようになってしまうことがあります。
色々と試したいところですが、クレジットも有限のためこのあたりにしておきます。
よりスムーズに繋げるアイデアとしては、明るい部屋のおもちゃの画像のプロンプトや画像そのものをAIに投げて、
こういうシーンにシームレスにつなげたいです。繋げる方法としては、左にレールが伸びていき、走り続けると明るい部屋に到着する。
などとそれっぽいトランジションを考えて提案し、それを英語プロンプト化してもらい、動画を生成してみるというものがあります。
この繰り返しで問題点(アーティファクト)が出てきたら都度それに対応したプロンプトを考えていくことになります。
このように指示をより複雑に細かく洗練させて行くことで、冒頭ご紹介したようなハイクオリティの作品になっていきます。
まとめ
長々とお読みいただきありがとうございました。
動画生成はまだまだ発展途上の分野であり、セオリーがどんどん変わっていく業界です。(数ヶ月単位で)
おそらくこの記事の内容も来年には陳腐化していることかと思います。
しかし、黎明期から最新情報にキャッチアップしていくことで、その流れにスムーズについていくことができるかと思います。
ご自身で試された方もいらっしゃるかと思いますが、なかなか思った画は一発ではできません。
まだ実用レベルではないからもう少し発展するまで待とう、と思っていらっしゃる方が大半かと思います。
おそらく実用レベルになったときには、いきなりAdobeソフトを触り始めたときの感覚のように、覚えることがたくさんで使いこなすのにハードルを感じることになります。
そうならないためにも、少しずつ触るだけでも、どこまでできてどこからできないのかが分かるようになります。
そうして新しい技術が出てきてそれらが解決された時、すんなり使い方を理解できることでしょう!
AIを使いこなすにあたって一番大切なことは、何ができないかを知っておくことです。
何ができないかを知っているということは、あなた自身がAIの進化の最先端にキャッチアップできたということと同義です。
なにか新しい技術が出てきたときに、できないことができるようになったということがニュースになりますが、できないことが理解できない人はそのニュースも当然理解できないことになります。
故に完全でないAIでさえも現時点から触って追いついておく必要があるわけです!
この記事が皆様の動画生成AIに触れるきっかけになりますと幸いです。
記事 三代




貴重なレポートありがとうございます!
非常に興味深い実証はもちろんのこと、「一番大切なことは、何ができないかを知っておくこと」のフレーズが心に刺さりました。大変勉強になりました(感謝)
実例があってすごく分かりやすかったです!
それにしても、最初に紹介されているForbesに紹介された映像、ほんとにすごいですね