






プロジェクションマッピング協会の三代です。
今回は、私が直近で研究している生成AI(特に画像や映像)の実用性についてお話しします。
「画像生成」と聞くと、多くの人はChatGPTで依頼すればある程度クオリティの高いものが作れて、しかもサブスクの範囲内で追加料金もかからない、そんなイメージを持たれていると思います。
しかし、実際にビジネスで使うとなると話は別。APIでの利用となるため生成毎にコストが発生してきます。
またコストだけでなく、精度、生成スピード、カスタマイズ性といった要素も重要になってきます。
この記事では、そうした観点から「どんな選択肢があるのか」「それぞれどんな特徴を持つのか」を整理しました。
「画像生成や動画生成をやってみたいけど、何から始めればいいのかわからない」「まずは全体像を知りたい!」という方は、ぜひ最後まで読んでみてください。
画像生成サービスとモデルの違い
まず最初に、ちょっとややこしい「モデル」と「サービス」の違いを整理しておきます。
モデル … 実際に画像を作るAIそのもの。例:Stable Diffusion、GPT image-1、DALL·E
サービス … モデルを使いやすい形にして提供してくれるもの。例:fal.ai、Replicate、ChatGPT
つまり、GPUやクラウド環境を直接いじらなくても、ブラウザや簡単なAPIで利用できるように整えてくれているのが「サービス」です。
画像生成モデルの全体像
前の章でも触れましたが、ChatGPTはあくまで「サービス」です。では、その裏側で実際に画像を生み出している「モデル」は何か。OpenAIで言えば GPT image-1 や DALL·E がそれに当たり、私たちはChatGPTというインターフェースを通してそれらを呼び出しています。ここからは、ビジネスで本当に使えるのはどのモデルか、コスト・精度・スピード・使い勝手の観点で見ていきます。
Stable Diffusion(Stability AI系)
まず押さえておきたいのが Stable Diffusion。オープンソースゆえにモデル自体は無料で使えます(GPUを借りれば当然その分の費用はかかります)。世界中のコミュニティが派生モデルを量産しており、かなりニッチな用途にも潜れるカスタマイズ性の高さは抜群です。映像制作の現場で絵コンテを自動生成し、細かな修正を何度も回す――そんな「手数勝負」のワークフローでは、生成を遠慮なく回せるSD系の強みがはっきり出ます。試行回数が増やせるので、結果的に到達点が上がる。しかも生成が速いのも周回向きです。
一方で、最新のクローズドモデルと比べると、精度・品質・汎用性では一歩譲ります。とくに「モデルが知らない概念」を描かせようとすると弱さが出やすいです。説明のためにプロンプトが長くなり、かえって効きが悪くなることがあります。導入面でも、ある程度のハードウェア知識と環境構築は避けて通れません。とはいえ、多くの画像生成サービスが裏側でSD系を使っているのも事実で、コストとライセンスの折り合いがつけやすい「ベースモデル」として、特化型の現場では今も主役級の存在感があります。
OpenAI系(GPT image-1)
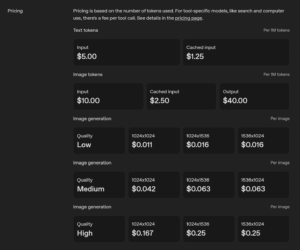
次に GPT image-1。ChatGPTの中からそのまま使える手軽さは大きな魅力です。ただ、コストは最大0.25USD/枚と高めで、一般的な相場で語られる0.04USD前後と比べると約6倍。かつては「高いけど画質で勝つ」という見立てもありましたが、2025年現在はスピード・クオリティ・価格の総合力で他社が追い抜きつつあります。正直、あえて選ぶ理由はないかな、、、という感想です。
一方で日本語の文字入れに関しては突出した性能を持っています。YouTubeのサムネ作成などでバズっていましたが、日本語のタイポグラフィを画像内に自然に載せるタスクでは依然として頭ひとつ抜けています。英語の文字なら代替候補はいくつもありますが、日本語となるとこのモデル一択です!
BFL Flux系(Flux Kontext Pro など)
Black Forest Labs は、Stable Diffusionの中心研究者が独立して立ち上げた新興勢力。看板の Flux シリーズは、「AIっぽいぼやぼやした画像」を脱して写実的でパキッとした絵を素早く出してくるのが持ち味です。現在のフラッグシップ モデルのFlux Kontext Pro はクローズドソースで、クラウドからの利用のみです。高性能なクラウド依存というだけあって速度が突出して早く(他のモデル最大2倍 最短で6秒ほど)、クオリティもかなり高いです。とくに部分編集、画像内テキストの置換や、複数画像の要素を破綻なく合成する類の作業で真価を発揮します。
面白いのはプロンプトの書き方がStabul diffusion系と少し変わる点です。モデル名の「Kontext」が示す通り、背景や意図を先に伝えると通りが良いです。「部屋の構成は保ったまま、この家具をここに配置してください」といった、やや会話に近い指示が強いです。状況の文脈を理解したうえで、こちらの意図に沿う形で自然な画像を生成してくれます。一方でただ長々と書けば良いわけではありません。長いプロンプトは、そのどこに注目すればよいのかモデルが迷うので、プロンプトの効きが悪くなることがあります。言葉の使い方もより厳密さを求められます。例えば“change” や “replace” は「指定したものを変えるが、他をできるだけ保つ」ようなニュアンスがあります。一方で“transform” はそのまま使うと「より広範囲に変化する/全体を変える可能性がある」というニュアンスになることが多いようです。全部日本語だと、変える(替える)という言葉にまとめられますが、より厳密な指示が良い結果をもたらす例として頭の片隅においておいていただけると良いかなと思います。
Google系(nanobanana / Gemini 2.5 Flash Image)
現時点で最有力と目されるのがGoogle系の nanobanana(Gemini 2.5 Flash Image)。生成速度はFluxより遅く、体感で約3倍かかるケースもありますが、そのぶん破綻の少なさと引き出しの多さは圧倒的です。とくに画風変換の幅が広く、アニメ調ひとつ取っても画風をたくさん知っているので、クリエイターの意図を反映しやすいと言えます。質感表現にも強く、「その質感をそもそも知らない」ことによる破綻が起きにくいのは大きな安心材料です。(例えば車を生成するときにつや消しのラッピングの質感で、と言ってもそのつや消しのラッピングの質感をモデルが知らないと再現できないという意味です。)
業界の空気感としても、「結局Googleがトップランナー」というムードは濃くなっています。LLMだけでなく画像生成の領域でも、Googleを追っていればトレンドから大きく外れない、そんな実感がたしかにあります。私自身、今後もしっかりキャッチアップしていくべき重要モデルとして位置づけています。(Googleの動画生成モデルのVeo3も業界ダントツのクオリティです。)
その他(ByteDance/Alibaba など)
その他も触れておきます。ByteDanceのSeedream はこの記事の中で一番最新のモデルです。
しかし学習の重心が特定画風に寄っているのか、モデルの「主張」が強く出がちです。クリエイターが後から独自の味付けを重ねようとしても、モデル側の色が勝ってしまい、発想の引き出しも狭く感じる場面がありました。
AlibabaのQwen Image Edit は対照的に、オープンソースで安価、ライセンスも緩やかで商用OKという扱いやすさが魅力です。モデルを丸ごと落として0円運用も技術的には可能(現実的な速度を出すなら結局クラウドが要る)。ただ、描写に「AIっぽい暖色」のトーンが出やすく、GPT感のある画像と言われそうです笑
AIでイラストを作るとChatGPTっぽい画像と揶揄されますが、その色をより濃くした感じです。
とはいえ画像編集系、特に英語の文字入れのような限定タスクでは手堅く働く場面があります。裏方として採用が進む可能性は十分あります。
流れの総括と、コスト感の現実
全体の流れとして、ローカル実行を掲げていたプレイヤーでさえ、クローズド+クラウドへ次々と舵を切っています。高品質と高速化を両立するための結論かなと感じています。生成のたびに課金が走るため一見割高に見えますが、GPUの時間単価で見積もると意外と高くなかったりします。特に企業導入では、ハードウェアの保守・更新費用も「生成コスト」に内包すべきで、総所有コスト(TCO)で比較すれば、実はクラウドの方が安くつくケースも割と多いです。クラウドベンダーの価格競争が激しく、大手クラウド(AWS等)を見ると高くて目ん玉が飛び出ますが、逆に新興勢力のクラウドインフラであれば実はその半額以下で使えるケースもあります。
実用性について考える
では、実際にビジネスの現場でどこまで使えるのか?
例えば広告バナー制作。
AIを使えば「女性が商品を持ってポーズを取る写真」を一瞬で生成でき、撮影スタジオや人件費の削減につながります。
しかし現場では大きな課題が残ります。
商品パッケージの文字が変わってしまう
女性の顔が別人になってしまう
色味や質感が正しく再現されない
最先端のGoogleモデルを使っても、「80点」まではAIで到達可能ですが、残りの「20点」を人間が修正しないといけないことが多いのです。
つまり「全部AIに任せられる」わけではなく、AIをどこで使って、どこは人間でやるのかを見極める必要があります。
上記は人間のワークフローをAIで置き換えていく、という観点からのアプローチでしたが、そもそもAIは新しい概念とも言えるので、作り方をゼロから考え直さないと行けないかもしれません。。。
最終イメージをAIに生成させようとしていますが、構成要素毎にクオリティ高く生成させて、それを機械的に合成させて、それをレビューして、というAIオーケストレーションの世界線では意外と今のAIたちだけでクライアントさんからOKをもらえるクオリティのものが作れてしまうかもしれません。
(余談ですが、現時点でのAIの広告制作は生成ではなくレビューがボトルネックになっているそうです。プログラミングと同じですね。)
お読みいただきありがとうございました。




コメント